
Obwohl wir alle im Alltag KI-Anwendungen begegnen, die mit Musik, Sprache oder Geräuschen zu tun haben, wird der Bereich Audio gerne übersehen. Dabei bietet er großes Potenzial. Neben Spracherkennung in Assistenzsystemen und Noise-Cancelling-Kopfhörern gibt es mittlerweile viele weitere Anwendungsmöglichkeiten in einer Vielzahl von Bereichen.
Im ersten Teil dieser Serie schauen wir uns ein paar Grundlagen der Signalverarbeitung an, um zu verstehen, was Audiodaten sind und wie wir sie digital verarbeiten können. Danach lernen wir typische Merkmale, sogenannte Features, kennen, die aus Audiodaten extrahiert werden können, um damit Machine-Learning-Algorithmen zu trainieren. Im zweiten Teil lernen wir dann praktische Tipps für Entwicklung einer eigenen KI-Lösung im Audiobereich sowie beispielhafte Use Cases aus unterschiedlichen Branchen kennen.
Grundlagen der Signalverarbeitung für Machine Learning
Wie entstehen Audiodaten überhaupt? Töne entstehen durch Schwingungen, zum Beispiel einer Gitarrensaite oder unserer Stimmbänder. Diese Schwingungen bewegen sich durch ein Medium, meist Luft. Die Anzahl der Schwingungen je Sekunde wird als Frequenz bezeichnet und in Hertz (Hz) angegeben. Wir Menschen können Töne zwischen etwa 20 Hz und 20.000 Hz hören, wobei wir langsame Schwingungen als tief, hohe als hoch wahrnehmen. Menschliche Stimmen bewegen sich in der Regel zwischen 250 Hz und 2.000 Hz. Die Stärke einer Schwingung wird durch die Amplitude (maximale Auslenkung) angegeben und beeinflusst, wie laut wir einen Ton wahrnehmen.
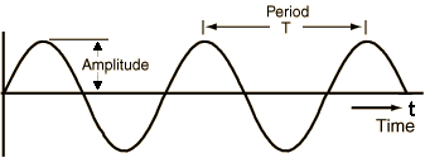
Abb. 1: Ein Sinus-Ton
Quelle: https://towardsdatascience.com/audio-deep-learning-made-simple-part-1-state-of-the-art-techniques-da1d3dff2504
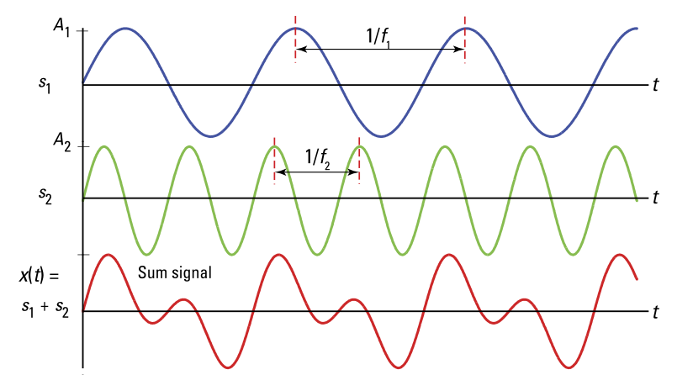
Eine einfache Schwingung ist der Sinus, der gleichmäßig mit einer bestimmten Frequenz schwingt (siehe Abb. 1). Ein solcher Ton kann künstlich erzeugt werden, natürliche Töne jedoch setzen sich aus Schwingungen mehrerer Frequenzen zusammen. So hört man bei einer Gitarre neben dem Grundton immer auch die Obertöne einer schwingenden Seite. Periodische Schwingungen lassen sich laut dem Satz von Fourier immer in mehrere Sinus-Schwingungen unterteilen (siehe Abb. 2). Im Vergleich zu periodischen Tönen, die wir als bestimmte Tonhöhe wahrnehmen, gibt es auch Geräusche, die durch unregelmäßige (nicht-periodische) Schwingungen entstehen, zum Beispiel Sprache.
Abb. 2: Summe zweier Sinus-Signale ergibt ein neues Signal
Quelle: https://stackoverflow.com/questions/51926684/plotting-sum-of-two-sinusoids-in-python
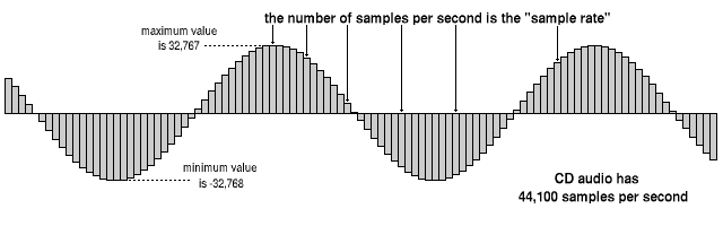
Aufzeichnen können wir Audio bekanntermaßen mit Mikrofonen. Die Mikrofonmembran erfasst, ähnlich wie unser Trommelfell, die Schwingung aus der Luft und wandelt sie in elektrische Spannungsschwankungen um. Um mit Audiosignalen digital arbeiten zu können, wird das kontinuierliche analoge Signal anschließend in ein digitales Signal umgewandelt. Dafür wird die Amplitude in einem bestimmten regelmäßigen Abstand (Abtastrate) abgetastet und jeder gemessene Amplitudenwert (Sample) dem nächsten Wert aus einer begrenzten Wertmenge (definiert durch die Bittiefe) zugeordnet, sodass ein wert- und zeitdiskretes Signal entsteht. Diesen Vorgang veranschaulicht Abb. 3. Eine übliche Abtastrate ist 44,1 kHz, das heißt, das Signal hat eine zeitliche Auflösung von 44.100 Samples pro Sekunde. Eine übliche Bittiefe (Auflösung) sind 16 Bit, das bedeutet, dass ein Sample einem von 2^16 = 65.536 Werten zugeordnet wird. Stereo-Signale bestehen aus zwei Kanälen, links und rechts.
Abb. 3: Umwandlung eines analogen in ein digitales Signal
Quelle: https://wiki.hydrogenaud.io/index.php?title=Sampling_rate
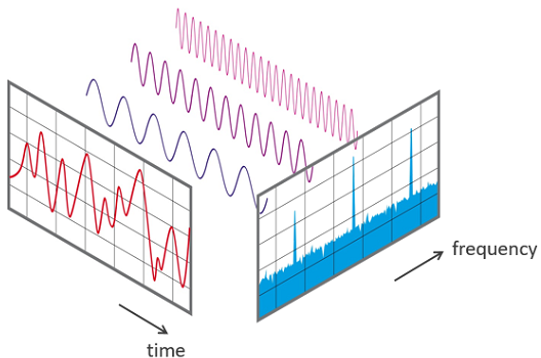
Mit der bekannten Wellenform wird die Amplitude eines Signals über die Zeit visualisiert. Anstelle in des Zeitbereichs kann ein (zeitlich begrenztes) Signal jedoch auch im Frequenzbereich betrachtet werden. Diese wird mithilfe der (schnellen) Fourier-Transformation aus dem Signal im Zeitbereich rekonstruiert und als sogenanntes Frequenzspektrum visualisiert. Abb. 4 zeigt die zwei verschiedenen Sichtweisen auf ein Audiosignal.
Abb. 4: Betrachtung eines Signals im Zeitbereich (links) und Frequenzbereich (rechts)
Quelle: https://www.nti-audio.com/de/service/wissen/fast-fourier-transformation-fft
Audio-Features für Machine Learning
Nun, da wir ein Grundverständnis für Entstehung und Merkmale eines digitalen Audiosignals entwickelt haben, können wir uns typische Merkmale anschauen, die im KI-Bereich verwendet werden. Diese werden Features genannt und dienen als Eingabe in ein Machine-Learning-Modell wie beispielsweise ein neuronales Netz.
Für traditionelle ML-Algorithmen werden Features typischerweise mithilfe von Methoden aus der digitalen Signalverarbeitung erzeugt. Diese Auswahl kann Expertise in der Signalverarbeitung sowie dem speziellen Use Case erfordern. Der Prozess der Merkmalsfindung wird auch Feature Engineering genannt. Beispiele für solche Merkmale werden im Folgenden aufgelistet.
Features im Zeitbereich
- Amplitude Envelope: die maximalen Amplitudenwerte jedes Frames für ein in Frames unterteiltes Signal. Diese sind ein Indikator für Lautstärke und werden z. B. für Musikgenre-Klassifikation genutzt.
- Root Mean Square Energy (RMSE): durchschnittliche Amplitudenwerte jedes Frames. Diese sind ebenfalls ein Indikator für Lautstärke, aber weniger anfällig für Ausreißer als Amplitude Envelope, und werden z. B. für Musikgenre-Klassifikation oder Audio-Unterteilung genutzt.
- Zero Crossing Rate (ZCR): gibt an, wie oft in der Wellenform die X-Achse gekreuzt wird. Sie ist ein Indikator für Geräuschhaftigkeit (noisiness) oder Präsenz von Stimme und wird z. B. für Musikgenre-Klassifikation oder Spracherkennung genutzt.
Features im Frequenzbereich
- Signal-to-Noise-Ratio (SNR) oder Signal-Rausch-Verhältnis (SRV): Verhältnis der Stärke des gewünschten Signals im Vergleich zum Hintergrundrauschen
- Band Energy Ratio (BER): gibt das Verhältnis von tiefen und hohen Frequenzbändern an und wird z. B. für die Unterteilung eines Audiosignals in Musik- und Sprachteile genutzt.
- Spectral Centroid (Schwerpunktwellenlänge): gibt den Schwerpunkt des Spektrums als Frequenzband an und wird als Mittel der Wellenlängen gewichtet mit ihren Amplituden berechnet. Dient als Indikator für die Klangfarbe und wird z. B. in der Audio- und Musikklassifikation verwendet. Weitere mit diesem Merkmal verwandte Features sind unter anderem Spectral Bandwidth, Spectral Spread und Spectral Flux.
Deep-Learning-Ansätze haben in den letzten Jahren dagegen die Möglichkeit gebracht, auch unstrukturierte Merkmale als Eingabe zu verwenden, aus denen das Modell die Features selbst lernt (Automatic Feature Extraction), wodurch kein aufwendiges Feature Engineering mehr notwendig ist. Diese Art der Eingabe bietet den Vorteil, dass Techniken aus dem Bereich der Bildverarbeitung genutzt werden können, so zum Beispiel Convolutional Neural Networks (CNNs), die neben der Bilderkennung so auch in der Spracherkennung gute Ergebnisse erzielen, indem eine visuelle Darstellung des Audiosignals als Eingabe dient. Zu solchen unstrukturierten Features gehören vor allem:
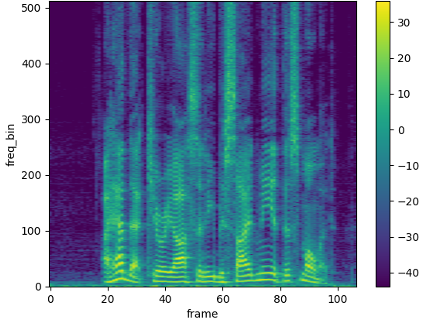
- Spektrogramm: Wir haben bereits gelernt, dass wir ein Signal im Frequenz- oder Zeitbereich betrachten können. Was aber, wenn uns der Frequenzverlauf über die Zeit hinweg interessiert? Dann können wir die Zeit-Frequenz-Bereich betrachten. Die Umwandlung erfolgt mithilfe der Kurzzeit-Fourier-Transformation (STFT), die das Signal in kleine Fenster unterteilt und anschließend für jedes Fenster das Frequenzspektrum rekonstruiert. Dabei besteht immer ein Trade-off zwischen zeitlicher und Frequenzauflösung (Frequenz-Zeit-Unschärferelation). Die drei resultierenden Dimensionen können wie in Abb. 5 (b) als Spektrogramm dargestellt werden: Zeit auf der X-Achse, Frequenz auf der Y-Achse und Amplitude durch die Farbskala. Jede „Spalte“ bildet also das Frequenzspektrum zu einem bestimmten Zeitpunkt ab.
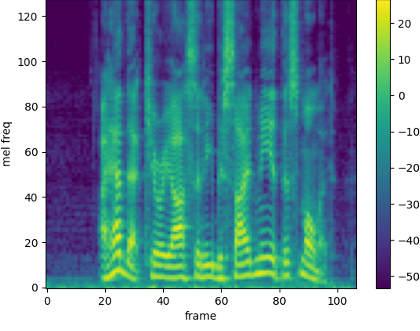
- Mel-Spektrogramm: Menschen können die Unterschiede tiefer Frequenzen besser wahrnehmen als die hoher. Daher wurde die ans menschliche Gehört angelehnte Mel-Skala eingeführt, eine logarithmische Skala, die die wahrgenommene Tonhöhe angibt. Ein Mel-Spektrogramm wie in Abb. 5 (c) ist also ein Spektrogramm, das auf der Y-Achse die Mel-Skala verwendet.
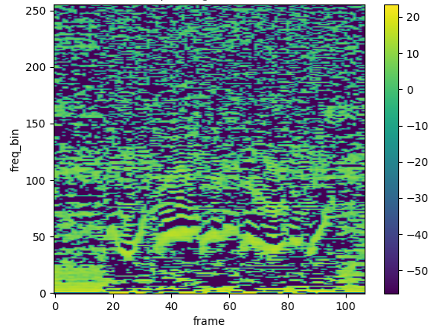
- Mel-Frequency Cepstral Coefficients (MFCCs): Diese Koeffizienten werden z. B. in der Spracherkennung und in der Musikanalyse verwendet und sind etwas weniger greifbar. Als Cepstrum wird das Spektrum des logarithmierten Frequenzspektrums eines Signals bezeichnet. Es ist eine Funktion der sogenannten Quefrenz, die als Maß für die Änderungsrate der Spektralbänder interpretiert werden kann. Die seltsamen Begriffe Cepstrum und Quefrenz sind tatsächlich korrekt, sie entstehen durch die Vertauschung der ersten Buchstaben. Die MFCCs sind vereinfacht gesagt die Koeffizienten, die dieses Mel-Frequency Cepstrum bilden und werden in gleicher Weise wie ein gewöhnliches oder Mel-Spektrogramm visualisiert, wie Abb. 5 (d) zeigt.
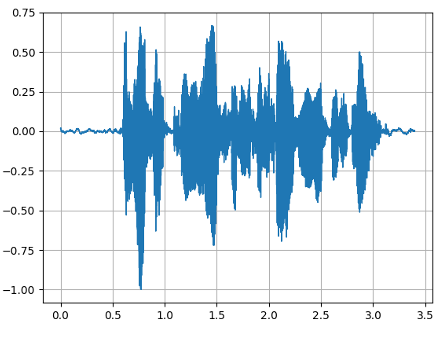
Abb. 5: Darstellung von Audio-Features einer Sprachaufnahme.
Quelle: https://pytorch.org/audio/stable/tutorials/audio_feature_extractions_tutorial.html
(a) Wellenform
(b) Spektrogramm
(c) Mel-Spektrogramm
(d) MFCCs mit N=2565 Koeffizienten
Quellen
- https://devopedia.org/audio-feature-extraction
- https://www.bonedo.de/artikel/akustik-grundlagen/
- https://towardsdatascience.com/how-to-apply-machine-learning-and-deep-learning-methods-to-audio-analysis-615e286fcbbc
- https://towardsdatascience.com/audio-deep-learning-made-simple-part-1-state-of-the-art-techniques-da1d3dff2504
- https://www.altexsoft.com/blog/audio-analysis/
- https://llaudioll.de/gdm-audio/
- https://www.musik-fromm.de/audio-grundlagen/
- https://www.elektroniktutor.de/digitaltechnik/ad_vergl.html
- https://www.sciencedirect.com/topics/engineering/spectral-centroid
- https://docs.twoears.eu/en/latest/afe/available-processors/spectral-features/
Im zweiten Artikel geht es weiter mit der Entwicklung einer KI-Lösung, Anwendungsbereiche und Beispiele.


